Let’s first describe a high level pseudo code of the algorithm:
- Generate AES expanded key
- XOR input data with encryption key
- For Rounds = 1 To NrRounds
- - SubBytes operation
- - ShifRows operations
- -
- - XOR with round key k[Rounds]
- copy result to output
As we can see on the previous pseudo code the AES-B algorithm follows the AES round steps described. This makes it easier to understand its functionality. First, we generate the expanded key or key schedule which basically takes the cipher key and performs the key schedule operation to determine the number of round keys necessary to encrypt the data. The number of round keys necessary to encrypt one block of information is related to the key length. In this example we are using a 128 bits key; therefore it will require in total 11 round keys, 1 for the initial round, 9 for standard rounds and 1 for the final round. After we expand the key, the input data is XORed which is basically the AddRoundKey operation for the initial round, followed by the execution of SubBytes, ShiftRows and MixCulumns operations. Note that these 3 operations will be executed only for the first 9 main rounds and when we reach the 10th round we exclude the MixColumns operation as described on previous posts.
// GLOBAL CONSTANTS
// --------------------------------------
//File name that contains the data to be encrypted
static const char *filename = "input.txt";
// INCLUDES
// --------------------------------------
#include <time.h>
#include <math.h>
#include <stdio.h>
#include <string.h>
// DEFINES
// --------------------------------------
// Amount of encryption tasks to perform
#define ITERATIONS 1
// AES Block size is 128 bits or 16 Bytes
#define AES_BLOCK_SIZE 16
// Amount of columns in the state. AES defines always 4 because it
//always encrypts 128 bit blocks. However, Rijndael can define more
#define STATE_COLUMNS 4
// Amount of AES rounds to execute depending on the key length
#define ROUNDS 10
// 1024 Bytes is the default start value when checking throughputs
#define START_VALUE 1024
//Assert used to compare encryption outputs against NIST Test Vectors
#define assert(x) if(!(x)){
printf ("\nGeneric assert " #x " has thrown an error\n");
}
double cpuEncrypt(char* in, int in_len, char* key, char* out)
{
int i;
unsigned char expkey[4 * STATE_COLUMNS * (ROUNDS + 1)];
clock_t start, end;
//Expand the key and store in key
ExpandKey (key, expkey);
start = clock();
for ( i = 0; i < in_len; i+=16 )
Encrypt( in+i, expkey, out+i );
end = clock();
return (end-start) / (double)CLOCKS_PER_SEC;
}
static void test_vectors()
{
int i = 0;
//NIST Test Vectors AES 128
//The following link contains the test vectors used below to guarantee
//that the functionality of the algorithm hast not been modified
//http://csrc.nist.gov/publications/nistpubs/800-38a/sp800-38a.pdf
unsigned char testPlainText[] = {0x50, 0x68, 0x12, 0xA4, 0x5F, 0x08,
0xC8, 0x89, 0xB9, 0x7F, 0x59, 0x80, 0x03, 0x8B, 0x83, 0x59};
unsigned char testKeyText[] = {0x00, 0x01, 0x02, 0x03, 0x05, 0x06,
0x07, 0x08, 0x0A, 0x0B, 0x0C, 0x0D, 0x0F, 0x10, 0x11, 0x12};
unsigned char testCipherText[] = {0xD8, 0xF5, 0x32, 0x53, 0x82, 0x89,
0xEF, 0x7D, 0x06, 0xB5, 0x06, 0xA4, 0xFD, 0x5B, 0xE9, 0xC9};
unsigned char out[16] = {0x0};
//Display plaintext to the user
printf("\n PlaintText: ");
for ( i = 0; i < AES_BLOCK_SIZE; i++)
printf("%x", testPlainText[i]);
printf("\n");
//Display key to the user
printf("\ Key: ");
for ( i = 0; i < AES_BLOCK_SIZE; i++)
printf("%x", testKeyText[i]);
printf("\n");
//Display ciphertext to the user
printf("\ CipherText: ");
for ( i = 0; i < AES_BLOCK_SIZE; i++)
printf("%x", testCipherText[i]);
printf("\n");
// Test encryption with OpenSSL
cpuEncrypt (testPlainText, sizeof(testPlainText), testKeyText, out);
//Display encrypted data
printf("\n CPU Encryption: ");
for (i = 0; i < AES_BLOCK_SIZE; i++)
printf("%x", out[i]);
//Assert that the encrypted output is the same as the
//NIST testCipherText vector
assert (memcmp (out, testCipherText, 16) == 0);
}
static double check_throughtputs ()
{
//Determines the amount of data to encrypt
int i, size;
size_t bytes_read;
double timer;
//Pointer to the file were the data to be process is located
FILE *file_input;
//Pointer to the input buffer, will hold the data read from the file
char *input_data;
//Pointer to the output buffer which will hold the encrypted data
char *output_data;
int fileSize;
//AES 128 Bit Key
unsigned char ckey[] = {0x00, 0x01, 0x02, 0x03, 0x05,
0x06, 0x07, 0x08, 0x0A, 0x0B, 0x0C, 0x0D, 0x0F, 0x10, 0x11, 0x12};
// Read the file into memory
file_input = fopen (filename, "rb");
fseek(file_input, 0, SEEK_END);
fileSize = ftell(file_input);
fseek(file_input, 0, SEEK_SET);
//Allocate memory for the inputa and output
//data depending on the file size
input_data = (char*)calloc (fileSize, sizeof(char));
output_data = (char*)calloc (fileSize, sizeof(char));
// It is important to know that the last 128 bit block
// to be encrypted can contain less than 128 bits to a
// for this test purpose input lenght is always aligned
// multiple of AES block size otherwise padding has to be implemented
bytes_read = fread (input_data, sizeof(char), fileSize, file_input);
fclose (file_input);
bytes_read = (int)(ceil (bytes_read / 16.0) * 16);
printf("\n%16s%16s%20s\n", "Total KB", "Seconds", "Throughput Mbps");
//Increment the data size to be encrpted by 2 starting with until
//the end of the file is reached
for ( size = START_VALUE; size <= fileSize ; size *= 2 )
{
timer = 0.0;
for ( i = 0; i < ITERATIONS; ++i ){
timer += cpuEncrypt (input_data, size, ckey, output_data);
}
printf ("%16i%16.3f%16.3f\n", size/1024, timer,
(size*8.0/(1024*1024))/ timer);
}
printf ("\t\n--------------------------------------------------\n");
//Free resources
free (input_data);
free (output_data);
return timer;
}
static void run_cipher(){
printf ("\nAES 128 Bit key");
printf ("\t\nNIST Test Vectors: ");
printf ("\t\n--------------------------------------------------");
test_vectors();
printf ("\n Test status: Passed\n");
printf ("\t\nAES on CPU Throughputs: ");
printf ("\t\n--------------------------------------------------");
check_throughtputs();
}
int main(int argc, char *argv[]){
run_cipher();
system("PAUSE");
return 0;
}
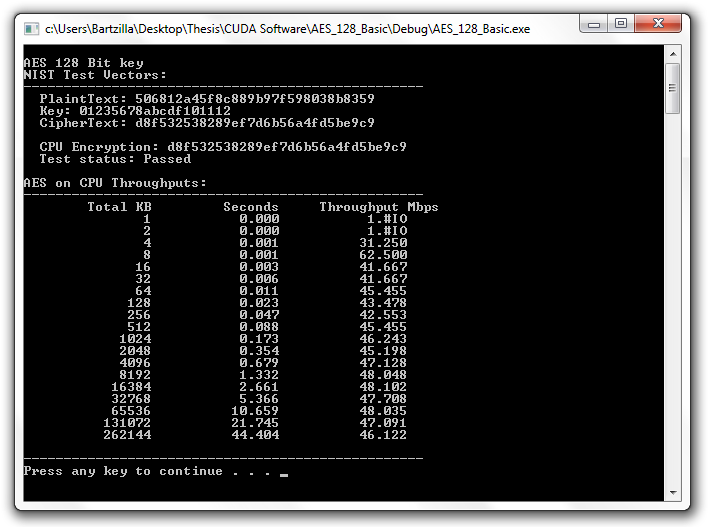 Throughputs obtained when encrypting a 256MB file on AES-B [click to enlarge]
Throughputs obtained when encrypting a 256MB file on AES-B [click to enlarge]
